COVID-19 has brought me more time to stay at home. Apart from taking a break from the day-to-day work schedule, I have had some time to go through my reading lists (or my hundreds of open tabs and windows), as well as rethinking how to better organise/restructure my information consumption habit.
We read a lot every day. How much can we actually retain? How much information that we once found useful can actually be used?
The Bad Habit
I have a bad habit regarding information consumption on computers/smartphones. When I come across some interesting sources or references but do not have the time/energy to go through it right away, I leave them open in the background for later.
With the tremendous amount of information that we receive every day, these tabs have piled up monstrously over time. They exceed not only my capacity to process them, but also my device’s (my computers occasionally reboot themselves alone, probably as a result of overloading).
Even though when I am available and motivated to process these references (COVID-19 does bring me the occasion), I have not been able to retain or reuse them effectively with my knowledge management habit.
Organisation, How and For What?
In the past, my habit of reference keeping heavily relies on bookmarks.
I save a webpage or article as a bookmark when I think it could be useful to look back at later. I put this reference into one of the bookmark folders/collections and tag it with the topics it can concern (e.g. typography, UI, CSS3).
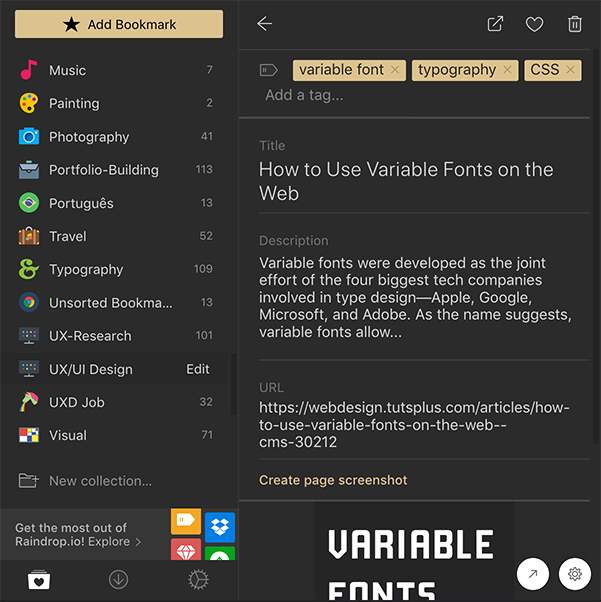
At times, I would add extra notes to summarise what this reference is about. It can be stored alongside the webpage bookmark (I use Raindrop for its cross-platform, multi-device interoperability), under the bibliography library entry (in Zotero), or in the document itself (PDF, mostly for scholarly papers and books). Sometimes, the bookmark is directly embedded in the notes which I am keeping for a project that I am working on (in this case, on Typora or nvALT).
The organisation seemed clear at the beginning. There is a defined space to store references of one nature. Their application is likely to be related to that defined scope.
Analogy: If I have a shirt, I would place it in my wardrobe. If it is a book, I would put it on my bookshelves. If it is a pen, I would store it in my stationery drawer/holder. If it is food, it would end up either in the pantry or the fridge. Easy-peasy.
Problems, however, slowly unveil themselves over time.
As the volume of references grows, so as their types and sources, I often find myself in the situation where I am not 100% sure where I should store them.
I could discover a blog post about some latest UX theories while I conduct research for a project. Shall I keep it with my existing notes (in Typora/nvALT), or in the collection folder in the browser extension Raindrop with topical tags? I might even write about the discovery afterwards and would like to properly cite it. Shall I register it in my Zotero library instead? If I save it in my project notes now, would I remember where to dig it out later—say—when I start writing my blog post sharing?
Thinking up to this point, I can already picture myself madly rifling here and there to try to call the source reference out.

Where is it? Where? (Image: Giphy)
Besides, information takes different shapes depending on the context. To maximise findability, more than often have I turned to the shortcut of saving the same source in multiple places (the associated notes, as well). This is rather unwise and excessive upfront manual work.
Problems do not stop at organisation.
The initiative of exploring resources, spending time to digest them and keeping them neatly in place is to facilitate and enrich my future work.
Shelving references at specific locations, highly attached to their source context, does not really help mobilise processed knowledge or encourage their subsequent application beyond their origin subject.
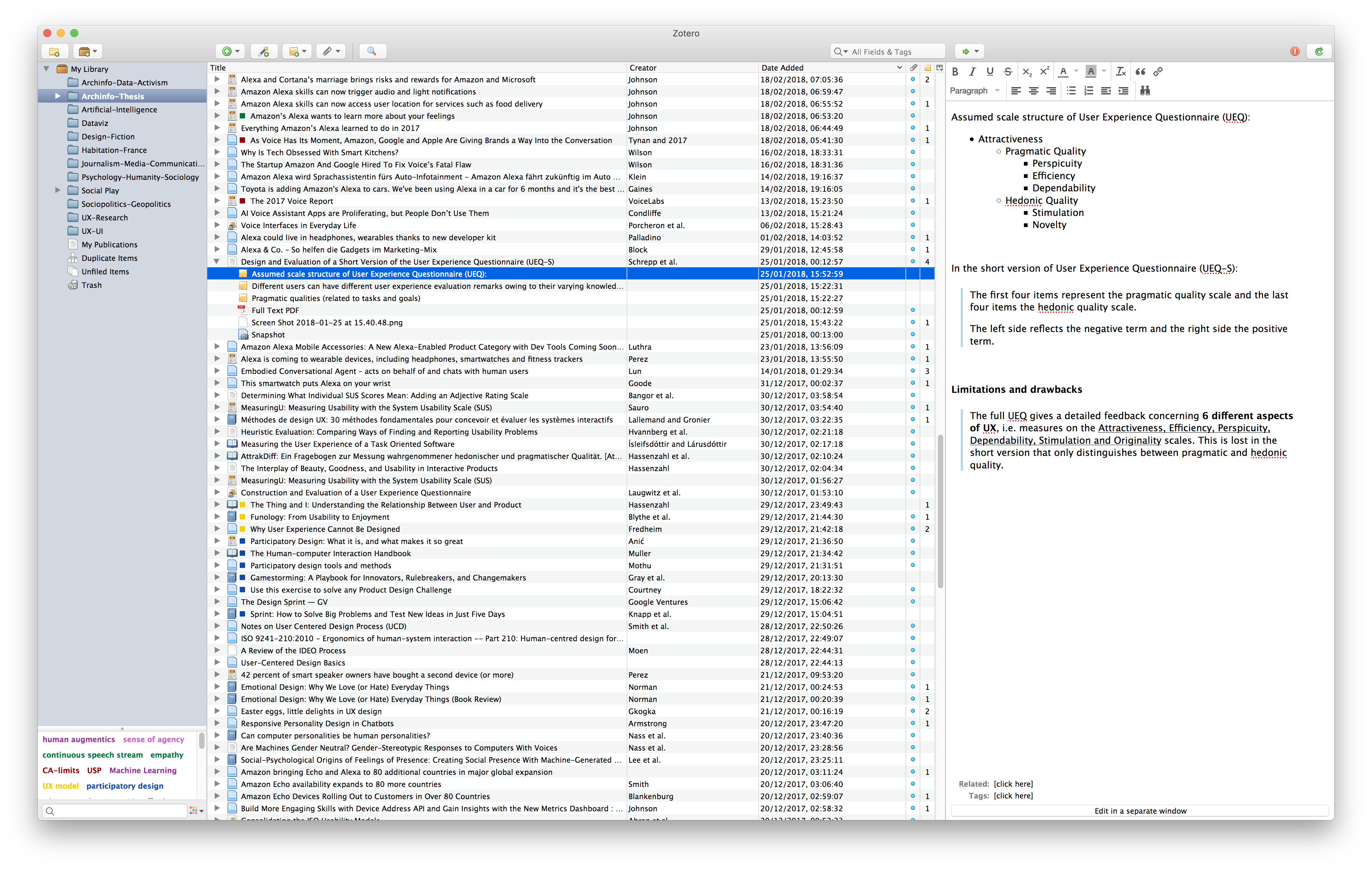
A Zotero entry example on User Experience Questionnaire by Martin Schrepp et al. I took notes on its evaluation methodology when I was writing my Master’s Thesis on UX for voice assistants. This is also useful for my professional work later on. Yet, it is still resting in the Master’s Thesis context and not readily recallable. There may even be a higher change where I would come across UEQ anew on search engines than on this exact entry.
Ideas, thoughts, insights are the most sparkling when they are kindled by unusual stimuli. Processed knowledge shall play a similar role, allow cross-disciplinary discoveries, and—the most importantly—be easy to spark when they might be inspiring to whatever subject I may eventually explore.
This escalates not only to an issue of bookmark/reference organisation, but personal knowledge management.
Solution Hunt: a Loosely Centralised, Morphable Library
It became clear to me that I want to establish a library of valued information and personal knowledge. One that is not only structured for management, but also conveniently exploitable for inspiration, and flexible to grow over time.

I spent quite some time trying to find the tool which allows a good balance between management effort, versatility and scaleability. Benchmarking tools in the market has led me to theories of knowledge management, as well as practical use cases sharing.
Despite my experiment with a few tools and attempts to follow people’s showcases and tutorials, I have not yet found the perfect fit. Methods and solutions are either too restrictive on media types, require too much janitor work, or too alien to my information consumption.
A less-than-perfect answer on which I am currently settling is Roam Research. It is a cloud-based outliner tool which allows great flexibility in organisation and cross-reference. It is still in close beta quite in the early stage of maturity and limited to textual information. The possibility of not having to worry about structure (easily malleable later) and just to focus on content is delightful. Thus it offers a relatively low entry to progressive summary and a scalable set-up.
Update Feb 2021: I have now moved to Obsidian and Foam for my reference keeping. They are both based on Markdown files and thus are not as atomic or flexible as the outliner counterparts Roam or RemNote. However, that also means better ownership control, storage of preference and pipelined Web publishing (some of my notes here). Both Obsidian and Foam have great community support and the latter is open-source, too!
While the knowledge library grows, the organisation required to keep it effective would also change. It is certainly an ongoing, evolving and organic process. Morphability is what Roam generously allows.
PS: Steve Yang has collected an extensive list of similar tools for networked knowledge management. It is constantly being updated by other collaborators!
This article is also published on Medium.